Search Thermo Fisher Scientific
Compound Discoverer 소프트웨어

시료에서 구조로, 경로에서 통찰로
데이터 세트의 크기에 관계없이 저분자 데이터를 전체 스캔 및 MSn 데이터에서 알려진 화합물 및 분자 경로로 변환합니다. 모체 확인 화합물 및 미지 화합물 식별을 위한 고급 소프트웨어 도구 모음을 제공하는 Thermo Scientific Compound Discoverer 소프트웨어를 소개합니다. Compound Discoverer 소프트웨어는 화합물 식별을 간소화하고, 시료 간의 실제 차이를 확인하며, 통합된 강력한 소프트웨어 워크플로우를 통해 생물학적 경로를 규명하여 귀중한 데이터로부터 빠르게 통찰력을 이끌어냅니다.
대사체학에서 바이오마커 발견, 환경 및 식품 안전, 제약 대사체 또는 불순물 식별, 추출물, 침출물, 법의학 또는 임상 독성학에 이르기까지 어떤 저분자 연구 애플리케이션에서든 Compound Discoverer는 저분자 구조 식별 소프트웨어에 대한 고유한 접근 방식을 제공합니다.
빠른 링크
Compound Discoverer 소프트웨어의 주요 장점
| 마우스 클릭 횟수 감소 | 미지 물질 확인 | 여러 시료의 실제 차이 측정 | 생물학적 경로 이해 |
|---|---|---|---|
| 맞춤형 워크플로우, 유연한 시각화 및 그룹화 도구를 사용하여 데이터 분석 및 프로세싱을 제어할 수 있습니다. 맞춤형 보고로 결과를 공유하거나 표적 분석을 위해 Thermo Scientific TraceFinder 소프트웨어로 직접 결과를 전송합니다. | 온라인 mzCloud 스펙트럼 라이브러리, 자체 보유한 Thermo Scientific mzVault 스펙트럼 라이브러리 및 수많은 타사 소스를 모두 검색하여 미지의 물질을 빠르고 확실하게 식별할 수 있습니다. | 시료 간에 실제 통계학적 차이를 빠르게 분석합니다. 상호 연결 디스플레이를 통해 연구 전반에서 성분의 추세를 확인하거나 여러 시료 그룹 간에 주요 관심 성분을 식별할 수 있습니다. | 대사체 유동 실험을 수행하고 Thermo Scientific Metabolika, KEGG 및 BioCyc 데이터베이스를 사용하여 경로를 확인할 수 있으며 검출된 화합물과 유동 정보를 경로에 직접 맵핑할 수 있습니다. |

저분자의 완전한 특성 분석 및 식별은 인체와 약물의 상호 작용에 대한 이해, 살충제의 환경적 영향 추적, 새로운 화합물 개발, 브랜드 평판 보호, 기초 연구 수행 등을 위해 필수적인 작업 중 하나입니다. eBook을 다운로드하여 자세한 내용을 확인하십시오.
Compound Discoverer 소프트웨어를 사용한 워크플로우 생성
Compound Discoverer 소프트웨어는 데이터 프로세싱을 위한 광범위하고 유연하며 맞춤형 설정이 가능한 툴킷을 제공합니다. 사전 정의된 워크플로우 템플릿이 포함되어 있어 즉시 실행할 수 있으며 실험용으로 특별히 설계된 프로세싱 워크플로우에 템플릿을 빠르게 적용할 수 있습니다.
워크플로우 편집기 및 프로세싱 흐름

Click to enlarge
The workflow editor is driven by templates that can be assembled into a workflow using drag-and-drop functionality. Your custom workflow then enables comprehensive data processing and visualization based upon your experimental needs.
The workflow editor is driven by templates that can be assembled into a workflow using drag-and-drop functionality. Your custom workflow then enables comprehensive data processing and visualization based upon your experimental needs.
연구 관리자

Click to enlarge
Study manager uses a wizard to guide you through the process of setting up a study, including defining sample types and other variables such as multiple time points or sample variants, such as different yeast strains.
Study manager uses a wizard to guide you through the process of setting up a study, including defining sample types and other variables such as multiple time points or sample variants, such as different yeast strains.
결과 분석

Click to enlarge
The Results analysis interactively links your data and allows you to choose how to visualize it. When selecting samples or components, each view is automatically updated based upon your selection(s).
The Results analysis interactively links your data and allows you to choose how to visualize it. When selecting samples or components, each view is automatically updated based upon your selection(s).
주석 및 생물학적 해석

Click to enlarge
Whether it is for unknown identification and spectral annotation or flux analysis and interpretation and mapping of biological information, Compound Discoverer software allows you to easily report your results, store your data and share your insights.
Whether it is for unknown identification and spectral annotation or flux analysis and interpretation and mapping of biological information, Compound Discoverer software allows you to easily report your results, store your data and share your insights.
Compound Discoverer 소프트웨어는 일관되고 정확한 고분해능 데이터를 제공하는 Thermo Scientific Orbitrap 기반 질량분석기의 강력한 성능을 활용합니다. 이 데이터를 통해 소프트웨어는 시료 간에 성분을 정렬하고, 원소 조성을 결정하고, 라이브러리를 일치시키고, 미지 물질을 식별할 수 있습니다.

Click to enlarge
The consistent mass accuracy and high-resolution spectral data from Orbitrap-based MS systems enables fine isotopic information to be obtained, as shown above for the compound davunavir. The resolution and accuracy provide confidence in elemental composition assignments and subsequent library matching, which can be further confirmed using MS/MS fragmentation information.
The consistent mass accuracy and high-resolution spectral data from Orbitrap-based MS systems enables fine isotopic information to be obtained, as shown above for the compound davunavir. The resolution and accuracy provide confidence in elemental composition assignments and subsequent library matching, which can be further confirmed using MS/MS fragmentation information.
결과 해석 및 통찰력 제공
연구의 복잡성이나 범위에 관계없이 모든 연구는 수 많은 정보가 포함된 복잡한 데이터를 생성합니다. Compound Discoverer 소프트웨어는 이러한 데이터에서 가장 중요한 정보를 얻기 위해 신중한 데이터 프로세싱과 통찰력 있는 데이터 검토 및 연결 기능을 제공합니다.
단일 시료를 분석하든 광범위한 대규모 시료 연구를 수행하든 관계없이 Compound Discoverer 소프트웨어는 다음 기능을 포함하여 저분자 미확인 데이터 프로세싱에 필요한 모든 것을 제공합니다.
- 미확인 피크 검출
- 고급 통계 도구
- 대화형 데이터 시각화 기능
- 화합물 주석 도구
- 통합 데이터베이스 및 질량 스펙트럼 라이브러리
- 생화학적 경로 매핑
- 비표적 안정 동위원소 라벨링 분석
- 대규모 검사를 위한 정규화 도구
연구 시료 크기에 관계없이 각 시료에는 풍부한 원시 데이터 포인트가 포함되어 있습니다. 이러한 데이터 포인트 중 일부는 서로 관련이 있으며 많은 데이터 포인트는 서로 관련이 없습니다. 이 복잡하지만 고품질의 MS 및 MS/MS 정보를 이해하려면 데이터를 축소해야 의미 있는 통찰력을 얻을 수 있습니다.

Click to enlarge
Within each data file there can be many millions of individual data points depending upon the relative complexity of the sample. To confidently obtain results for each sample, and across samples, each data file must have its array of data points aligned with features detected, e.g., a single compound with multiple isotopic peaks may also have numerous adducts. Once the data has been reduced from raw data into features, components can be assembled and identified.
Within each data file there can be many millions of individual data points depending upon the relative complexity of the sample. To confidently obtain results for each sample, and across samples, each data file must have its array of data points aligned with features detected, e.g., a single compound with multiple isotopic peaks may also have numerous adducts. Once the data has been reduced from raw data into features, components can be assembled and identified.
여러 애플리케이션별 템플릿 중 하나를 사용하거나 이러한 템플릿 중 하나를 편집하여 빠르고 쉽게 데이터를 프로세싱할 수 있도록 끌어서 놓기 기능을 사용하여 워크플로우를 설정할 수 있습니다. 각 프로세싱 단계는 주어진 워크플로우 트리 내의 '노드'에 의해 설명되며, 사용자의 연구 요구 사항에 따라 데이터 프로세싱 및 해석을 유도하기 위해 이를 연결할 수 있습니다. 소프트웨어 개발자 키트 또는 R 또는 Python과 같은 맞춤형 스크립트를 사용하여 새 노드를 만든 다음 스크립팅 노드와 함께 사용하여 필요에 맞게 워크플로우를 조정할 수 있습니다.

Click to enlarge
An example of a pre-defined workflow template for untargeted metabolomics. This template is designed to find and identify differences between samples. Each node is linked and performs a specific task. Here, retention time alignment is performed before unknown compounds are detected and grouped across all samples within the study. Elemental compositions are predicted using the accurate mass data, with compounds identified using the mzCloud mass spectral library and MS/MS information. Where there is no match from mzCloud, ChemSpider is used. For results with a ChemSpider match, mzLogic is used to rank results by likelihood of a match. Resulting compounds are then mapped to biological pathways using Metabolika. If QC samples are present, then normalization is performed, and subsequent differential analysis calculated (t-test or ANOVA).
An example of a pre-defined workflow template for untargeted metabolomics. This template is designed to find and identify differences between samples. Each node is linked and performs a specific task. Here, retention time alignment is performed before unknown compounds are detected and grouped across all samples within the study. Elemental compositions are predicted using the accurate mass data, with compounds identified using the mzCloud mass spectral library and MS/MS information. Where there is no match from mzCloud, ChemSpider is used. For results with a ChemSpider match, mzLogic is used to rank results by likelihood of a match. Resulting compounds are then mapped to biological pathways using Metabolika. If QC samples are present, then normalization is performed, and subsequent differential analysis calculated (t-test or ANOVA).
Compound Discoverer 소프트웨어 인터페이스는 질문과 가장 관련성이 높은 정보를 표시하여 결과 검토를 간소화합니다. 각 플롯 및 표가 연결되어 검토 중인 화합물 또는 시료를 반영하도록 보기가 즉시 업데이트됩니다.

Click to enlarge
The compound results table default layout where the chromatographic overlay (top left) shows the extracted ion chromatograms for each related adduct, as shown in the selected compound spectra (top right). The results table can be tailored to display the information relevant to your study, such as compound annotation, retention time, peak areas, statistical information, MS2 spectral match, and more.
The compound results table default layout where the chromatographic overlay (top left) shows the extracted ion chromatograms for each related adduct, as shown in the selected compound spectra (top right). The results table can be tailored to display the information relevant to your study, such as compound annotation, retention time, peak areas, statistical information, MS2 spectral match, and more.

Click to enlarge
Compound Discoverer software allows you to open related tables to quickly access the information used to generate annotations. This figure shows the information related to searching the mzCloud mass spectral library (bottom) along with the related experimental and library fragmentation spectra displayed as a mirror plot (top right).
Compound Discoverer software allows you to open related tables to quickly access the information used to generate annotations. This figure shows the information related to searching the mzCloud mass spectral library (bottom) along with the related experimental and library fragmentation spectra displayed as a mirror plot (top right).

Click to enlarge
From volcano plots from differential analysis (left), S-Plots from partial least squares discriminant analysis (middle), and hierarchical clustering analysis (right), it is easy to visualize complex data sets and determine what is statistically different using Compound Discoverer software. Each plot is active, so data points selected in the plot can be marked in the results tables and vice versa, helping determine the cause of observed differences or similarities and tracking compounds in complex data sets.
From volcano plots from differential analysis (left), S-Plots from partial least squares discriminant analysis (middle), and hierarchical clustering analysis (right), it is easy to visualize complex data sets and determine what is statistically different using Compound Discoverer software. Each plot is active, so data points selected in the plot can be marked in the results tables and vice versa, helping determine the cause of observed differences or similarities and tracking compounds in complex data sets.
Compound Discoverer 소프트웨어 애플리케이션
Compound Discoverer 소프트웨어는 대사체학에서 환경, 식품 안전 및 약물 개발에서 법의독성학에 이르기까지 다양한 애플리케이션에 사용할 수 있습니다.
대사체학 연구는 매우 복잡할 수 있기 때문에 고품질의 포괄적인 데이터의 수집은 통찰력을 얻기 위해 데이터를 분석하는 것과 마찬가지로 매우 까다로운 작업입니다. 완전한 시료 적용 범위를 보장하기 위해서는 일반적으로 데이터 종속 획득(DDA) 실험을 위한 포함 및 제외 목록 생성에 상당히 많은 양의 수동 작업이 필요합니다.
자동화된 워크플로우인 AcquireX를 사용하면 자동화된 백그라운드 이온 배제 및 실제 시료 성분에 초점을 맞춘 데이터 수집과 함께 향상된 MS/MS 샘플링을 통해 모든 시료 성분을 직접 조사할 수 있습니다.

Click to enlarge
AcquireX generates an exclusion list from a blank run (matrix matched). Then, an injection of the sample, followed by feature detection and component assembly, populates the inclusion list with compounds detected in the samples. A series of iterative DDA injections follow. Each injection is informed from the previous one, minimizing redundant fragmentation spectra and maximizing relevant spectra and metabolite annotations.
AcquireX generates an exclusion list from a blank run (matrix matched). Then, an injection of the sample, followed by feature detection and component assembly, populates the inclusion list with compounds detected in the samples. A series of iterative DDA injections follow. Each injection is informed from the previous one, minimizing redundant fragmentation spectra and maximizing relevant spectra and metabolite annotations.

Click to enlarge
Using DDA with AcquireX significantly increases the number of unique compounds with high-quality fragmentation spectra, so you obtain a more comprehensive picture of what is in your samples, as well as increasing the depth of decision-making MS/MS information available.
Using DDA with AcquireX significantly increases the number of unique compounds with high-quality fragmentation spectra, so you obtain a more comprehensive picture of what is in your samples, as well as increasing the depth of decision-making MS/MS information available.
AcquireX와 Compound Discoverer 소프트웨어를 위한 다른 활성화 도구를 결합하면 MS/MS 스펙트럼이 없는 화합물의 수가 크게 줄어들고 신뢰성 있는 식별 화합물과 순위가 매겨진 추정 식별 화합물의 수가 크게 증가합니다.

Click to enlarge
Using DDA with AcquireX improves data quality and creates a significant increase in the number of compounds with MS/MS spectra, resulting in improved mzLogic ranking and higher mzCloud similarity scores, ultimately providing higher overall confidence in compound identification and putative unknown identification.
Using DDA with AcquireX improves data quality and creates a significant increase in the number of compounds with MS/MS spectra, resulting in improved mzLogic ranking and higher mzCloud similarity scores, ultimately providing higher overall confidence in compound identification and putative unknown identification.
안정 동위원소 라벨링은 비표적 대사체학 연구를 지원할 수 있으며, Compound Discoverer 소프트웨어는 이러한 워크플로우를 지원하는 다양한 데이터 검토 및 시각화 도구를 제공합니다. Compound Discoverer 소프트웨어는 참조 파일에 있는 비표지 화합물의 포뮬라를 기반으로 표지 화합물(동위원소)을 자동으로 검출합니다. 프로세싱이 완료되면 여러 파일에 걸쳐 반응을 확인하거나 Metabolika 경로에 중첩하여 교환율(또는 결합 비율)을 그래프로 표시할 수 있습니다.

Click to enlarge
Stable isotope labelling uses the high-resolution mass spectral data from Orbitrap-based MS, where isotopologues can easily be detected and the respective elemental compositions determined. Compound Discoverer software makes it easy to visualize the amount of label incorporation and resulting isotopic distribution with the ability to map powerful qualitative and quantitative flux analysis information directly onto biological pathways in Metabolika.
Stable isotope labelling uses the high-resolution mass spectral data from Orbitrap-based MS, where isotopologues can easily be detected and the respective elemental compositions determined. Compound Discoverer software makes it easy to visualize the amount of label incorporation and resulting isotopic distribution with the ability to map powerful qualitative and quantitative flux analysis information directly onto biological pathways in Metabolika.
Compound Discoverer 소프트웨어는 통계 분석 및 데이터 정규화 섹션에서 설명한 대로 다양한 일변량 및 다변량 분석을 수행할 수 있습니다.
Compound Discoverer 소프트웨어에는 구조적으로 지능적인 탈알킬화/디아릴화(dealkylation/diarylation) 및 일반 대사 예측 기능이 포함되어 있어 관심 대사체를 찾아서 식별하고 보고할 수 있습니다. 불순물과 분해 산물의 식별은 유사한 워크플로우를 따르며, 다양한 소프트웨어 도구와 맞춤형 접근 방식을 통해 복잡한 시료에서 관련 성분을 확실하게 검출할 수 있습니다.
단편화 스펙트럼의 구조 주석에 사용되는 단편 이온 검색(FISh)은 미지 물질의 구조적 규명을 가능하게 하는 것 외에도 잠재적인 변형 부위의 위치를 확인할 수 있습니다.

Click to enlarge
The FISh scoring node enables fragment structure annotation and uses the Thermo Scientific HighChem Fragmentation Library for real data from more than 52,000 fragmentation schemes to help localize (bio)transformation. Exact matches are shown in green, with transformation-shifted matches highlighted in blue (above), showing how the site of transformation is identified.
The FISh scoring node enables fragment structure annotation and uses the Thermo Scientific HighChem Fragmentation Library for real data from more than 52,000 fragmentation schemes to help localize (bio)transformation. Exact matches are shown in green, with transformation-shifted matches highlighted in blue (above), showing how the site of transformation is identified.

Click to enlarge
Pattern scoring allows you to flag compounds that match user-specified natural or artificial isotopic patterns. Including and using additional traces such as UV, PDA, CAD and analog, such as radio label traces, as shown above, ensures that minimal potential metabolites, impurities or degradants are missed.
Pattern scoring allows you to flag compounds that match user-specified natural or artificial isotopic patterns. Including and using additional traces such as UV, PDA, CAD and analog, such as radio label traces, as shown above, ensures that minimal potential metabolites, impurities or degradants are missed.
Compound Class Scoring 노드는 아무 것도 누락되지 않도록 하는 또 다른 도구를 제공합니다. 특정 화합물 등급에서 하나 이상의 알려진 분자로부터 생성된 대표 단편 집합을 사용하여 관련이 있거나 동일한 화합물 등급의 다른 성분을 식별합니다.

Click to enlarge
The Compound Class scoring node allows you to identify compounds that are structurally related, ensuring that nothing is missed, from metabolites to potentially toxic or harmful extractables, leachables or degradants.
The Compound Class scoring node allows you to identify compounds that are structurally related, ensuring that nothing is missed, from metabolites to potentially toxic or harmful extractables, leachables or degradants.
Compound Discoverer 소프트웨어는 매트릭스 간섭을 줄이고 관련 질량 결함을 통해 특정 화합물 등급을 표적화하여 시료의 복잡성을 줄임으로써 복잡한 데이터 세트를 더 빠르게 식별, 감지 및 검토할 수 있도록 합니다.

Click to enlarge
Upper left shows the Total Ion Chromatogram (TIC) for a sample in bile matrix, illustrating the potential complexity and matrix interferences present; bottom left shows the resulting trace following the use of Multiple Mass Defect Filtering (MMDF) and how it can be used to effectively simplify complex matrix samples such as bile, feces, blood, and plasma. The plot on the right demonstrates how the mass defect plot can be used to visualize data and mine using Kendrick formulas, for example unknown polymer identification. All data is interactively linked between plots and data tables within Compound Discoverer software to streamline data review.
Upper left shows the Total Ion Chromatogram (TIC) for a sample in bile matrix, illustrating the potential complexity and matrix interferences present; bottom left shows the resulting trace following the use of Multiple Mass Defect Filtering (MMDF) and how it can be used to effectively simplify complex matrix samples such as bile, feces, blood, and plasma. The plot on the right demonstrates how the mass defect plot can be used to visualize data and mine using Kendrick formulas, for example unknown polymer identification. All data is interactively linked between plots and data tables within Compound Discoverer software to streamline data review.
Compound Discoverer 소프트웨어는 식품 불순물의 대사 영향 및 구조적 조성을 분석하고 토양과 물의 환경 오염물을 검출하는 데 사용할 수 있습니다. 환경 및 식품 안전 연구에서 미지 화합물이 식별되면 사중극자 또는 고분해능 MS 기반 기술을 사용한 고처리량 스크리닝이 필요한 경우가 많습니다. Compound Discoverer 소프트웨어를 사용하면 조직 내에서 메서드(Method) 전송의 부담을 줄이기 위해 Thermo Scientific TraceFinder 소프트웨어와 함께 사용할 새로운 라이브러리나 기존 mzVault 라이브러리 또는 대상 목록으로 직접 데이터를 내보낼 수 있습니다.
Compound Discoverer 소프트웨어는 미확인 남용 약물 대사체와 구조적으로 관련된 신합성 약물을 검출합니다. 예를 들어, 많은 신약에 유사한 구조가 포함되어 있으며 Compound Class Scoring Node는 공통 단편 이온에 대해 검출된 화합물의 점수를 산정하는 데 사용할 수 있으므로 특징적인 단편에 기반하여 신약을 찾을 수 있습니다. 이 정보는 스크리닝 방법으로 이전되어 지속적으로 증가하는 신약 및 대사체를 따라잡는 데 도움이 될 수 있습니다. Compound Discoverer 소프트웨어에서 사용 가능한 여러 워크플로우를 사용하여 미지의 화합물을 식별한 후 데이터를 새 mzVault 라이브러리 또는 기존 mzVault 라이브러리로 직접 내보낼 수 있습니다. 또는 사중극자 또는 고분해능 MS 기반 기술을 사용하는 스크리닝 및 정량 분석을 위한 Thermo Scientific TraceFinder 소프트웨어와 함께 사용할 수 있는 표적 목록으로도 내보낼 수 있습니다.
* 법의학용으로만 사용 가능합니다.
Compound Discoverer 소프트웨어용 활성화 도구
포괄적인 데이터 세트를 이해하고 해석하기 위해 몇 가지 도구가 사용됩니다. Compound Discoverer 소프트웨어는 수많은 온라인 및 오프라인 리소스에 액세스할 수 있으며, 미지 화합물을 식별하는 데 도움이 되는 직접적인 스펙트럼 일치가 없는 경우 지능형 알고리즘을 사용할 수 있습니다.
- mzCloud는 광범위한 온라인 고급 질량 스펙트럼 단편화 데이터베이스입니다.
- mzLogic은 수백만 개의 사용 가능한 구조 데이터베이스와 mzCloud의 광범위한 질량 스펙트럼 단편화 라이브러리를 결합하여 직접적인 질량 스펙트럼 일치가 없는 경우 미지 물질 구조의 순위를 지정하는 데이터 분석 알고리즘입니다.
- mzVault는 온라인에 액세스할 수 없거나 독점권이 있는 자체 라이브러리를 사용해야 할 때 사용할 수 있는 리포지토리입니다. mzCloud에서 MS/MS 레벨 콘텐츠에 액세스하거나 맞춤형 로컬 라이브러리를 생성하는 기능을 제공합니다.
- 단변량(uni-variate)및 다변량(multi-variate) 통계 분석을 위한 통계 분석 및 데이터 정규화 도구
이러한 도구를 통해 식별된 모든 화합물을 연결할 수 있으므로 다음 분석 단계에서 사용할 데이터를 간편하게 선택하고 여러 소스로 내보낼 수 있습니다.

Click to enlarge
You can direct creation or expansion of mzVault spectral libraries or TraceFinder software format lists using text lists, mass lists, inclusion and exclusion lists, enabling you to streamline your analyses and subsequent targeted screening and/or quantitative analysis with minimal effort.
You can direct creation or expansion of mzVault spectral libraries or TraceFinder software format lists using text lists, mass lists, inclusion and exclusion lists, enabling you to streamline your analyses and subsequent targeted screening and/or quantitative analysis with minimal effort.
Compound Discoverer에 사용할 수 있는 강력한 활성화 도구에 대해 자세히 알아보기

광범위한 저분자 애플리케이션을 포괄하는 mzCloud의 광범위한 구조 및 화학적 다양성은 미지 물질 식별에 있어 절대적인 신뢰성을 보장합니다.
광범위한 메타데이터와 결합된 포괄적인 고분해능 MS/MS 및 다단계 MSn 스펙트럼을 사용하는 세계 최대의 LC-MSn 참조 스펙트럼 라이브러리 및 가장 광범위하게 선별된 질량 스펙트럼 라이브러리로 강력한 미지 물질 식별 기능을 제공합니다.

온라인 데이터베이스 또는 사용자 제공 구조에서 구조적 검색의 모든 기능을 활용하여 MSn 및 하위 구조 스펙트럼 매칭을 통해 더 많은 미지 물질을 확실하게 식별할 수 있습니다.
세계에서 가장 규모가 큰 질량 스펙트럼 단편화 라이브러리 mzCloud는 어떻게 만들어졌습니까?
많은 전구체 및 MSn 단편화 스펙트럼은 mzCloud 내의 각 화합물별로 스펙트럼 트리 형태로 논리적으로 구성됩니다. 각 스펙트럼 트리 수준은 MSn 단계를 상징하며 여기서 최상위 수준은 n=1 또는 전구체 스펙트럼에서 시작합니다. 각 수준은 후속 단편의 광범위하고 대표적인 범위를 보장하기 위해 다양한 실험 조건을 사용하면서 데이터가 수집됨에 따라 수많은 스펙트럼을 포함할 수 있으며, 이는 고품질 검색 결과의 가능성을 높여줍니다.

mzCloud의 스펙트럼 트리에 대한 개략적 표현. 다중 극성이 있는 특정 화합물(ESI +/-)과 다양한 부가물에 대하여 MS 스펙트럼을 획득합니다. 각 전구체는 다양한 단편화 기법(CID, HCD)과 여러 충돌 에너지를 사용하여 각각의 단편화 수준(MS2, MS3, MS4 등)에서 남김없이 단편화되어 각 라이브러리 항목에 대한 포괄적인 스펙트럼 정보 트리를 생성합니다.
각 라이브러리 항목에 대한 광범위한 데이터는 Compound Discoverer와 Mass Frontier 데이터 분석 소프트웨어 패키지에서 제공하는 확실한 적합성과 데이터 시각화를 통해 실험적으로 얻은 데이터와 라이브러리 콘텐츠의 데이터가 서로 일치하는지 확인하면서 정확한 화합물을 식별하는 데 매우 중요합니다. 추가 도구에는 스펙트럼 라이브러리 화합물 항목만으로 식별할 수 없는 미지 물질을 신뢰성 있게 식별하기 위해 광범위한 단편화 정보를 사용하는 mzLogic 등이 있습니다.

라이브러리 검색에서 일치하는 항목이 없으면 어떻게 됩니까? mzCloud에 포함된 포괄적인 단편화 정보를 계속 활용할 수 있습니다. mzLogic은 스펙트럼 유사성 및 하위 구조 정보(전구체 이온 핑거프린팅)를 통해 이 모든 정보를 활용하여 실제 미지 물질에 대한 최상의 후보 물질을 제안할 수 있습니다.
저분자 미지 물질에 맞는 스펙트럼이 없는 경우 어떻게 식별할 수 있습니까?
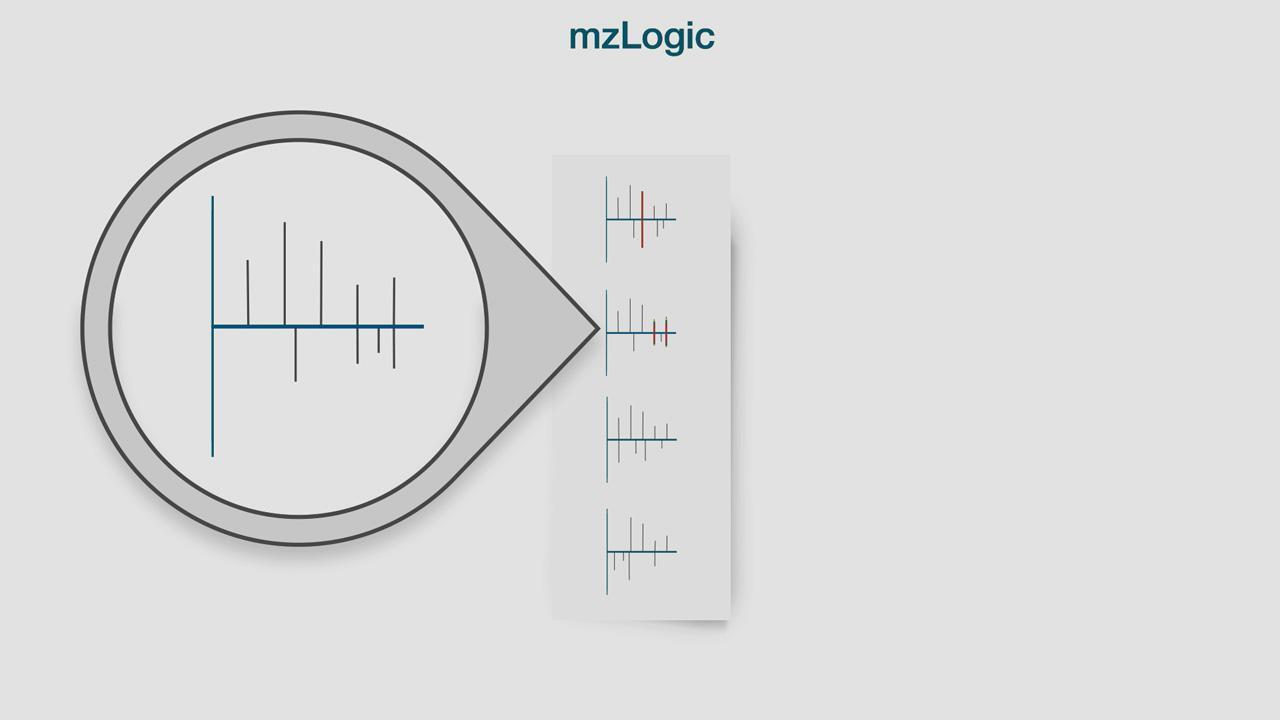
스펙트럼 라이브러리 유사성 검색과 화학 물질 데이터베이스 검색을 결합하여 실제 단편화 데이터를 최대한 활용할 수 있습니다.
Metabolika로 반응 경로를 생성, 편집 및 검색할 수 있습니다. 반응 경로를 생성 및 편집할 수 있는 고품질 그래픽 기능과 다양한 유기체에 대하여 선별되고 주석 처리된 370개 이상의 생화학적 경로(모듈에 이미 포함됨)를 통해 경로 지식을 쉽게 공유할 수 있습니다.
Metabolika의 정보는 단편화 예측 및 mzLogic에도 사용되어 미지 화합물 식별의 가능성을 더욱 높입니다.

Click to enlarge
An example of biological pathway, which can be edited or added to, included in Metabolika.
An example of biological pathway, which can be edited or added to, included in Metabolika.
또한 안정 동위원소 라벨링 분석을 위해 Metabolika에 교환율(또는 결합 비율)을 포함시켜 경로를 보다 포괄적으로 파악할 수 있습니다.

Click to enlarge
Combining stable isotope labelling with the visualization capabilities of Metabolika, allows you to overlay exchange rate information to provide a highly visual way of reviewing and reporting qualitative flux analyses.
Combining stable isotope labelling with the visualization capabilities of Metabolika, allows you to overlay exchange rate information to provide a highly visual way of reviewing and reporting qualitative flux analyses.
Metabolika와 더불어 Compound Discoverer 소프트웨어는 KEGG 및 BioCyc 생물학적 경로 데이터베이스를 모두 지원합니다. 화합물 맵핑은 두 가지 방법으로 표시할 수 있습니다. 상황에 따라(특정 화합물 관찰 등) 이 화합물이 어떤 경로로 맵핑되었는지 확인하거나 경로 목록에서 시작하여 주어진 경로에 맵핑된 모든 화합물을 시각화하는 전역 보기(global view)를 사용할 수 있습니다. 예를 들어, mzCloud를 사용하여 검출된 화합물을 확인할 수 있으며 그 결과 데이터는 내장된 경로에서 색상별로 구분됩니다.
데이터는 획득한 지식이므로 고유한 가치가 있습니다. mzVault는 오프라인에서 mzCloud의 MS2 레벨 스펙트럼 데이터에 액세스하여 검색을 수행하거나 자체 스펙트럼 라이브러리 정보를 저장하는 기능을 제공합니다. 스펙트럼 정보와 자체적으로 획득한 지식을 Compound Discoverer에서 새로운 라이브러리 또는 기존 라이브러리로 자동 전송할 수 있습니다. 이 라이브러리는 Compound Discoverer 또는 TraceFinder 소프트웨어를 사용하여 검색하거나 Thermo Scientific Mass Frontier 소프트웨어를 사용하여 편집할 수 있습니다.
광범위한 온라인 구조 데이터베이스와 구조 또는 하위 구조를 제안하기 위한 mzLogic을 함께 사용하더라도 가끔 미지 물질이 여전히 미확인 상태로 남을 수 있습니다. 이 정보를 이전에 식별된 독점 화합물 라이브러리와 함께 저장하고 전에 식별한 적이 있는지 여부를 확인하는 데 이 정보를 사용하는 것이 유용할 수 있습니다.
다양한 애플리케이션에서 Compound Discoverer 소프트웨어는 새로운 환경 오염물질뿐만 아니라 신합성 약물 및 대사체 모두에서 미지 물질을 확실하게 식별할 수 있는 수단을 제공합니다. 이러한 애플리케이션 중 일부에서 다음 단계는 TraceFinder 소프트웨어와 함께 사중극자 또는 고분해능 MS를 사용한 더 많은 처리량 식별 및/또는 정량 분석이거나 타사 패키지를 사용한 추가 분석일 수 있습니다.
좋은 실험 설계는 모든 분석에 매우 중요합니다. 특히 통계 연구의 경우 관찰된 잠재적 추세가 실험 효과에 기인한 것이 아니라 실제 변화를 기반으로 발생하도록 하는 것이 중요합니다. 따라서 대규모 연구의 정규화를 달성하기 위해 통합된 품질 관리(QC) 시료를 사용하는 대규모 연구를 위한 프로토콜이 있습니다.

Click to enlarge
Using pooled QC samples, which are analyzed throughout data acquisition, allows for the correction of batch-effects over time. Correction for each sample is performed individually, the upper plot shows a curve fitted to the QC samples, with the bottom plot showing the resulting data set after correction. This capability is based upon a peer-reviewed methodology published by Dunn et. al. in Nature Protocols. Compound Discoverer software provides the capability to also view the impact of any changes to the data pre- and post- normalization according to this protocol.
Using pooled QC samples, which are analyzed throughout data acquisition, allows for the correction of batch-effects over time. Correction for each sample is performed individually, the upper plot shows a curve fitted to the QC samples, with the bottom plot showing the resulting data set after correction. This capability is based upon a peer-reviewed methodology published by Dunn et. al. in Nature Protocols. Compound Discoverer software provides the capability to also view the impact of any changes to the data pre- and post- normalization according to this protocol.
Compound Discoverer 소프트웨어에 포함된 강력하고 광범위한 통계 도구 모음은 데이터/화합물 그룹의 변화 및 양을 이해하는 데 도움이 되도록 완벽하게 연결되어 있습니다.
통계적 분석은 대사, 환경, 식품 안전 및 불순물, 법의학, 임상, 불순물, 추출물 및 침출물 연구에서 다양한 분석에 사용할 수 있습니다. 시차 분석, ANOVA, PCA에서 PLS-DA에 이르기까지 다양한 단변량 및 다변량 분석을 수행할 수 있는 기능과 이러한 도구의 출력과 워크플로를 통한 복합 식별의 결과를 고도의 그래픽 및 대화형 방식으로 결합하여 데이터에 대한 깊은 통찰력을 제공하여 쉽게 보고하고 공유할 수 있습니다.

Click to enlarge
Demonstrating the connectivity of data within Compound Discoverer software, the data points highlighted by blue circles in the Volcano Plot (bottom right) are selected within the Compound Table (bottom left). Selecting any compound in any plot automatically updates all plots to show the relevant data. The interconnected tools enable you to rapidly identify differences and the compounds or groups of compounds responsible for those differences. Additionally, it streamlines follow-on confirmation by giving you the ability to filter and review the relevant data.
Demonstrating the connectivity of data within Compound Discoverer software, the data points highlighted by blue circles in the Volcano Plot (bottom right) are selected within the Compound Table (bottom left). Selecting any compound in any plot automatically updates all plots to show the relevant data. The interconnected tools enable you to rapidly identify differences and the compounds or groups of compounds responsible for those differences. Additionally, it streamlines follow-on confirmation by giving you the ability to filter and review the relevant data.
Compound Discoverer 소프트웨어는 복잡한 데이터 세트 및 관계를 시각화하는 여러 가지 방법을 제공하므로 모니터 간에 여러 플롯을 추가하여 이러한 관계를 추적 및 확인하면서 데이터를 보다 잘 이해할 수 있습니다.

Click to enlarge
From Principal Components Analysis (PCA) for unbiased review of data to supervised techniques like Partial Least Squares – Discriminant Analysis (PLS-DA) and the use of S Plots (left) identify compounds that give rise to any observed grouping of samples. Hierarchical Clustering (center) not only shows the clustering of samples along the x-axis, and clustering of compounds on the y-axis, it provides user-configurable heat mapping to visualize any clustering. Box Whisker Charts (right) allow visualization by groupings, time points, and more, with dynamic.
From Principal Components Analysis (PCA) for unbiased review of data to supervised techniques like Partial Least Squares – Discriminant Analysis (PLS-DA) and the use of S Plots (left) identify compounds that give rise to any observed grouping of samples. Hierarchical Clustering (center) not only shows the clustering of samples along the x-axis, and clustering of compounds on the y-axis, it provides user-configurable heat mapping to visualize any clustering. Box Whisker Charts (right) allow visualization by groupings, time points, and more, with dynamic.
복잡한 데이터 세트를 철저히 검토하고 차이 발생을 유발한 성분을 평가한 후에는 식별된 화합물에 의해 변화/차이가 발생했는지 확인하기 위해 보다 실질적인 분석이 필요할 수 있습니다. 검토된 화합물을 Compound Discoverer 소프트웨어에서 다양한 출력 형태로 쉽게 내보내 추가 분석을 용이하게 할 수 있습니다. 자세한 내용은 "사용자 정의, 로컬 라이브러리 및 데이터 전송" 섹션을 참조하십시오.
화합물 간의 관계를 탐구하여 데이터 세트에 대한 추가 정보와 통찰력을 얻을 수 있습니다. Molecular Networks를 사용하면 변환 및 스펙트럼 유사성(예: 다양한 I단계 및 II단계 변환)을 기반으로 분석에서 화합물 간의 관계를 대화식으로 탐색할 수 있습니다.

Click to enlarge
The fully interactive Molecular Networks visualization browser allows you to view your data in a different way. Identified compounds are shown by nodes (circles) and when a relationship is identified, the nodes are connected. Selecting a node (compound) or connection (transformation) displays pertinent information (right) about the identified compound and the relevant transformation(s). All of the visualized data can be interactively filtered using thresholds, data quality information or text search for specific compounds or transformations.
The fully interactive Molecular Networks visualization browser allows you to view your data in a different way. Identified compounds are shown by nodes (circles) and when a relationship is identified, the nodes are connected. Selecting a node (compound) or connection (transformation) displays pertinent information (right) about the identified compound and the relevant transformation(s). All of the visualized data can be interactively filtered using thresholds, data quality information or text search for specific compounds or transformations.
단편 이온 검색(FISh)을 사용하면 이론적인 단편 예측 또는 실험 MSn 데이터로 획득한 모체 화합물의 단편화 패턴에 기반하여 구조적으로 유사한 화합물을 빠르게 스크리닝할 수 있습니다. 모체 화합물 구조와 잠재적 대사체는 대부분의 매트릭스 관련 배경 이온을 걸러내어 관련 화합물을 빠르고 쉽게 식별하는 데 사용됩니다. FISh는 I단계 및 II단계 생체변환의 광범위한 목록과 맞춤형 목록을 작성할 수 있는 기능을 제공합니다.

Click to enlarge
In addition to filtering the structurally similar compounds, FISh automatically localizes transformation sites, labels, and applies color-coding to fragments common to the parent and filtered results. In the Mirror Plot example shown here, exact matches to proposed metabolite fragments are shown in green and transformation shifted matches are blue.
In addition to filtering the structurally similar compounds, FISh automatically localizes transformation sites, labels, and applies color-coding to fragments common to the parent and filtered results. In the Mirror Plot example shown here, exact matches to proposed metabolite fragments are shown in green and transformation shifted matches are blue.
52,000개 이상의 단편화 방식, 217,000개 이상의 개별 반응, 256,000개 이상의 화학적 구조 및 동료 평가 문헌의 216,000개 이상의 디코딩 메커니즘을 포함하는 HighChem 단편화 라이브러리를 포함함으로써 FISh는 추정 대사물질 또는 기타 잠재적 구조에 대한 구조적 할당을 지원하는 강력한 도구입니다. FISh는 추정 구조에 대한 단편화 구조를 제안할 때 실제 데이터를 사용하여 신뢰성을 높이고 점수를 계산하여 주어진 구조 후보가 단편화 데이터를 얼마나 잘 설명할 수 있는지 알려줍니다.

이 백서(white paper)에서는 질량 스펙트럼 라이브러리를 사용한 저분자 식별 문제를 다룹니다. mzCloud 스펙트럼 라이브러리 및 mzVault 소프트웨어는 루틴(routine) 및 연구(research) 애플리케이션에서 저분자 식별 문제를 해결하도록 설계되었습니다.
Compound Discoverer 소프트웨어 동영상
사용자 및 과학자들이 제공하는 Compound Discoverer 소프트웨어의 강력한 기능에 대해 자세히 알아보려면 아래 동영상을 시청하십시오.

저분자 특성 분석 및 식별에서 의사 결정을 위해 클라우드 기술을 활용해 보십시오. 질량분석법 소프트웨어를 포함하는 클라우드 기반 기술의 접목은 실험실의 새로운 흐름이 되고 있습니다. 지금 바로 미래의 문제를 해결하십시오.
Compound Discoverer 소프트웨어 주문 가이드
관련 소프트웨어 애플리케이션 및 기술

질량분석 장비와 소프트웨어에 관련한 모든 지원 요구사항을 위한 하나의 리소스. 실험을 시작할때 관련 기술 정보를 얻고, 팁(tip) 및 트릭(trick)을 보실 수 있으며, 몇몇 일반적인 문제들에 대한 답을 찾아 보실수 있습니다.